|
Phase invariant features
|
Most voice recognition systems use features which are sensitive to only the amplitude
signal spectrum. By using (typically overlapping) windows of short duration, such systems
trade off phase invariance with phase sensitivity.
To envision input sounds which would be indistinguishable to these features, and therefore
indiscriminable to the recognition systems, we can randomize the phase of a speech signal
within overlapping windows of varying sizes.
|
|
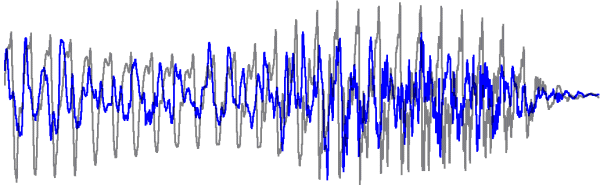
Figure 1: 2000 samples of speech (in black) are phase scrambled within overlapping windows of 256 samples,
and re-projected back into the time domain (shown in red). The signals are clearly very different.
|
| Window size |
Original
|
512
|
256
|
128
|
64
|
32
|
| Source: female-clean.wav |

|
|
|
|
|
|
|
Table 1: Examples of speech which has been phase scrambled within overlapping windows of varying length
|
Cepstral subspace projections
|
Features used in recognitions systems are often based upon the
cepstral domain. Typically the cepstrum is computed and the top N
coefficients are kept for recognition. Thus, any variations which
occur in coefficients beyond the top N cannot be distinguished by
these features.
By projecting onto this N dimensional subspace, and adding noise of varying power
in the dimensions off of this subspace, we can create a wide variety of signals which
would be invariant to such systems.
|
|
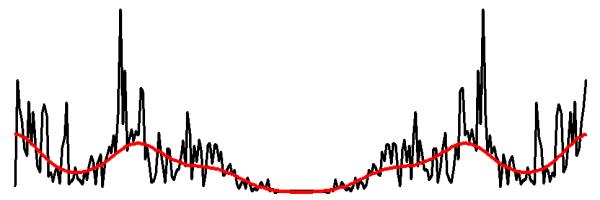
Figure 2: The spectrum of a block of speech shown in black, is projected
onto a 10 dimensional subspace of the cepstral domain, and
projected back resulting in the spectrum shown in red.
|
|
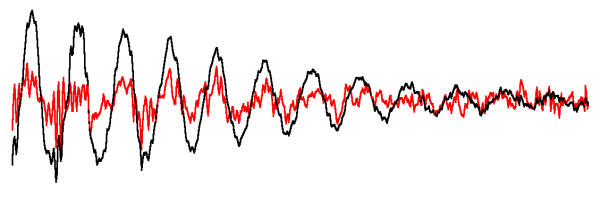
Figure 3: A section of the signal shown in black, after projection onto a
onto a 10 dimensional subspace of the cepstral domain, shown in red.
|
| Cepstral Features |
All
|
30
|
30
|
30
|
30
|
20
|
20
|
20
|
20
|
10
|
10
|
10
|
10
|
| Orthogonal Noise |
None
|
None
|
10%
|
20%
|
50%
|
None
|
10%
|
20%
|
50%
|
None
|
10%
|
20%
|
50%
|
Source: female-noisy
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Source: male-clean
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Source: male-noisy
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Source: test2
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Table 2: Several examples of speech projected onto subsets of cepstral
coefficients, with varying levels of noise added in the orthogonal
dimensions.
|
Page loaded on July 01, 2025 at 10:00 PM.
Page last modified on
2006-05-27
|
Copyright © 1997-2025, Jeremy S. De Bonet.
All rights reserved.
|
|