Jeremy S. De Bonet : Example Driven Image Database Querying
| Resume | |||||||||||||||||||||||||
| RESEARCH | |||||||||||||||||||||||||
|
|||||||||||||||||||||||||
| Projects | |||||||||||||||||||||||||
| Web Hacks | |||||||||||||||||||||||||
Abstract
|
 View Slides From Presentation |
Motivation: |
|---|
|
There exists no way to directly measure the similarity between the content of images. Without the ability to measure similarity, it is impossible to treat images as queryable, searchable, or sortable data. As a result queries for images are typically satisfied by manually searching through all images in the entire image database. To automate this process, new techniques are needed to extract from an image qualities which can be used to make measurements of similarity. |
Previous Work: |
|---|
|
There are several organizations which support projects to develop new computer-vision algorithms to provide an automatic or semiautomatic method for performing such tasks. To ask if one image is similar to another, one must specify, in some way, what criterion are to be used to make such a comparison. The principal developments to date, have come from the Query By Image Content (QBIC) project at IBM [1], the Visual Information Retrieval project at Virage [2], and the PhotoBook project in the MIT Media Lab [3]. All these projects form an image query using a single example image, and the selection of weights which determine the relative importance of each global image feature in measuring similarity. These projects have concentrated their effort on extracting a small number (fewer than ten) global image features. These features are essentially a collection of independently developed techniques such as color histograms, texture histograms, shape boundary descriptors, and eigenimages. |
Approach: | |
|---|---|
|
| |
|
The large set of measurements we make of each image are based on the responses of a collection of non-linear filter-networks. The responses of each filter-network in the collection are combined to form a characteristic signature for each image. These signatures used to measure the similarity between the images in the database and the group of example-images. The similarity measure of each image in the database is then used to rank and sort the images, satisfying the query. |
Difficulty: |
|---|
|
This query paradigm requires the extraction of a large, general and robust set of image features. Such a set must be complete enough to incorporate all the characteristics of an image that could potentially be needed criterion to measure similarity. |
|
To meet this requirement, we use as our image features the responses of a large class of filter-networks. The numerical response of each filter network in this class is becomes element in what we call the characteristic signature of the image. It is this characteristic signature which is then used as the basis for image comparison. |
|
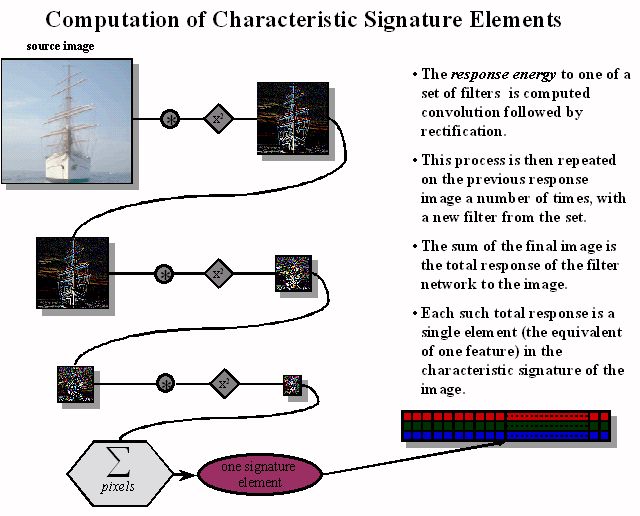
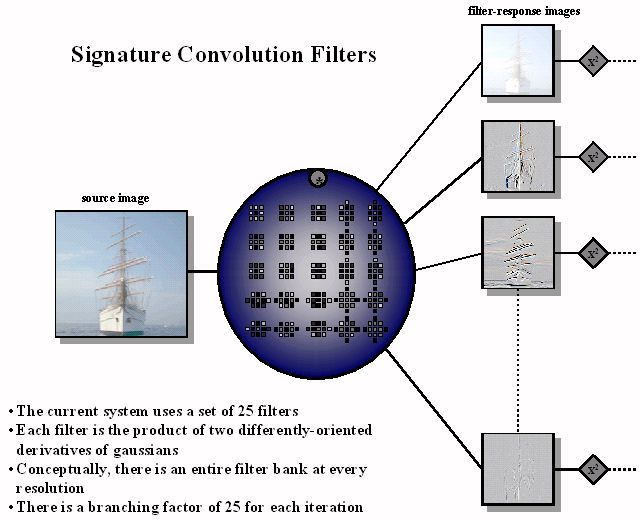
Each filter network consists of several repetitions of a linear convolution operation, followed by a non-linear operation. The normalized sum of the result of these operations is (i.e. the response of the network) is a single element of the characteristic signature. A single path through this network is outlined in Figure 1, while the branching factor at each level is depicted in Figure 2. |
|
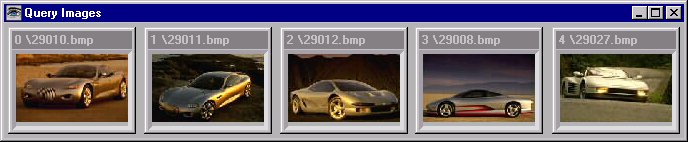
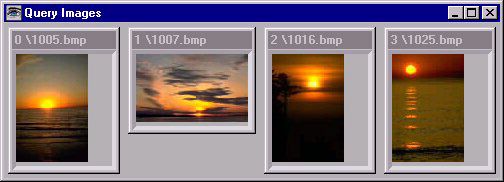
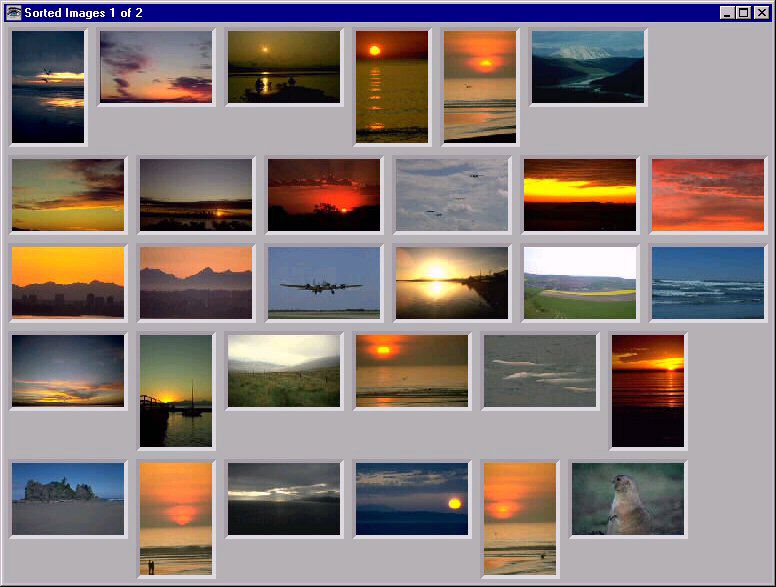
The results of a typical query from this system are shown in Figure 3. Because of the lack of structure, and large variety of colors in the sunsets, simple methods based on just form and color could not satisfy such a query. |
|
|
Figure 1: A single filter network from the network set, which generates one element of the characteristic signature. |
|
|
Figure 2: At each level there are 25 filters, which are applied generating a set of 45,000 distict image measurements. |
Impact: |
|---|
|
With a functional metric over images, computers will be able to manipulate image data in the same way as they can currently manipulate text and numerical information. That is to say, they will be able to retrieve and sort information based on its visual content. This ability will cause a drastic shift in the tasks for which we use computers; a host of new applications will become possible. |
Future work: |
|---|
|
Future work in this area includes increasing the robustness of the underlying image representation, and building models based upon these techniques which will allow for unconstrained image recognition. |
|
|
|
Figure 3: An example of the results of a query on this system. The top 25 images are shown. Because of the large variations in chromatic content, and lack of salient forms within the result images, its is clear that methods based only on color and shape metrics could not yield such results. |
Reference Links: |
|---|
|
[1] QBIC Project, IBM Research, http://wwwqbic.almaden.ibm.com |
|
[2] Virage, http://www.virage.com |
|
[3] Vision and Modeling Research Group, MIT Media Lab, Photobook Project, http://www-white.media.mit.edu/vismod/demos/photobook |
|
Jeremy S. De Bonet jsd@debonet.com |

|
|
|
|