Jeremy S. De Bonet & Chris P. Stauffer: Learning to Play PacMan Using Incremental Reinforcement Learning
BODY| Resume | |||||||||||||||
| RESEARCH | |||||||||||||||
|
|||||||||||||||
| Projects | |||||||||||||||
| Web Hacks | |||||||||||||||
Abstract
We have applied an embodied intelligence approach to learn optimal playing strategies for both PacMan and the opponent ghosts. Over many thousands of iterations, the linear creature-centered perceptron network is continually modified with reinforcements based on rewards gained through out each game. To make such a formidable learning task feasible, we begin training with extremely simple boards, then increase their complexity once simpler, basic behaviors have been learned.
Games have been a prominent theme within Machine Learning, especially in the domains of reinforcement learning and genetic programming. One class of games, which simulate competitions for survival in some synthetic world approach the problem of opposing "players" who learn the domain simultaniously. Work in this area has been predominantly in "Tom & Jerry"-type competitions where the two competitors have some restrictions on movement, speed, or available energy. They typically however, do not attempt to incorporate what we will call environmental policy learning.
In most "Tom & Jerry" competitions the objective is to learn to predict and optimally react to your opponents actions in a world with few environmental constraints on direction or speed of motion. Because of this trivial environment the behaviors learned in these experiments are simple responses to the action of the opponent. For example behaviors like "chase", "bolt", "juke", "random walk" are learned. Given the more complex environment of PacMan, more sophisticated behaviors and policies, perhaps even long term planning could be learned.
Introduction
The world of PacMan is more complex than the environment of a typical competition scenario, because of several of the games characteristics:- Spatial configurations of walls severely limits mobility of both preditor and prey; including such possibilities as dead-ends which force policy reversals.
- Motion-blocking walls permit more complex "hiding" and "dodging" behaviors.
- Consumption of "Powerdots" temporarily reverse the predator prey relationship; necessitating a behavioral response due to environmental changes.
- Gradual changes in environment occur as a result of actions taken by the competitors.
- Extreme changes in environment occur as the the playing board increases.
- Topologically toriodal environment (i.e. the wrap around at board edges) prevents simple "run away" behaviors.
1 : The PacMan Environment
The domain over which PacMan and the Ghost must learn consist consists of external environmental constrains determined by the current level, and by their current policies and the policies of their opponents.The environment can be described with a matrix which encodes the presence or absence of each of the environmental components listed in Table 1.1.
|
|
|
|
| ||
|---|---|---|
2 : Internal Representation
| When given to the system as input, the world is represented by a 2d array which identifies the contents of each cell on the game board. To make a system reason about these possible arbitrary labels would be quite difficult. For example consider if 1=PowerDot, 2=Ghost, 3=Dot, there is no linear relationship between label and goodness. To overcome this we split the world into bit planes where each bit indicates the presence or absence of a particular component at a particular position on the board. |
|

| Each creature has binary detectors for each of the possible elements of the environment for a 10x10 grid centered on the creature. This defines the current environment for the creature. |

3 : Our Reinforcement Learing Paradigm
|
Because we use a perceptron-like network as our fundamental representation of
each of the creatures evaluation functions, we have implicitly assumed that the
factors in the world are linearly separable.
This is in fact not the case, as in some situations an optimal policy might
include conditions such as exclusive or, which cannot be represented with a
linearly separable mechanism.
|
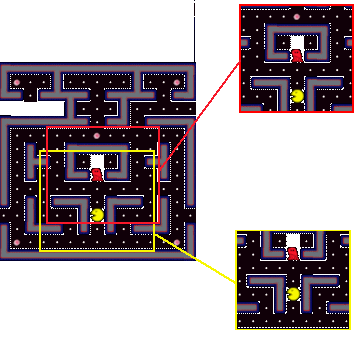
| Given our creature-centric internal representation of the world state, as depicted in Figure 3.1, a perceptron network over this space can be represented by a real valued 3 dimensional array. Each creature has a weighting matrix which defines the desirability of having each of the elements in each particular location for each possible move. By taking the dot product analog of this array with the state of the world represented as a 3 dimensional binary array, we can essentially record the response of this network to the word-state stimulus. |
|

|
By comparing the responses of four separate networks, each which encodes
the drive to move in one of four directions, we can determine the
most preferred action for the creatures.
It would be possible to use four matrices for Up, Down, Left and Right
but this would take longer to learn than one matrix which is
directionally specific. This matrix is rotated and multiplied by the
current environment to attain the expected benefit of making that
move.
|
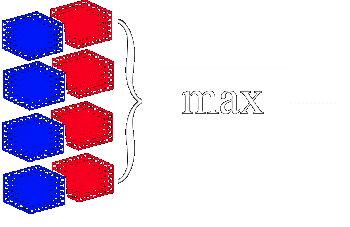
The update rule for the perceptron network is based on a reinforcement learning scheme. Essentially upon competition for each game, each the value assigned to each move is the immediate score acquired on that turn plus some percentage of the value of the previous move.
4 : Testing Procedure
The testing procedure involved introducing the ghost and pacman to environments of increasing complexity. By starting with a very simple environment, the pacman would begin with reinforcing very basic behavior such as avoiding walls, avoiding ghosts, eating pacman, eating edible ghosts, and eating dots.
After a number of iterations, the board was changed and more complex behaviors needed to be developed. There is a chance that simple behaviors could be unlearned, if they are not as useful at higher levels, but our intention is to learn behaviors which can be generally applied to most situations.
These behaviors could be categorized as simple, general drives(i.e. a will to live, a desire for food, adversion moving into walls). Each of these drives are competing against each other, but depending on the strength of the reinforcement, certain drives will dominate. For example, the drive to avoid getting eaten should outweigh the drive to eat dots.
Figure 4.1:
|

Figure 4.2:
|

Figure 4.3:
|
Figure 4.4:
|
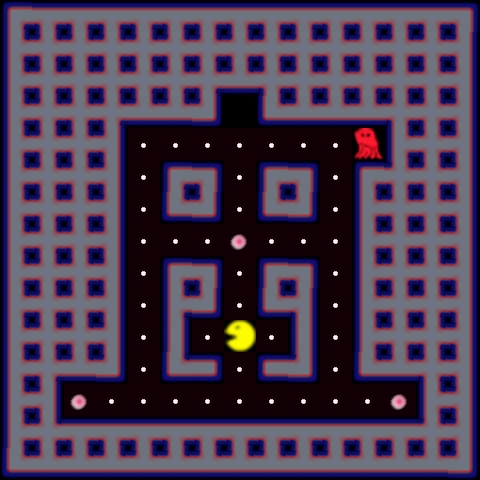
Figure 4.5:
|
5 : The Perceptron Network As Accumulated Drives

|
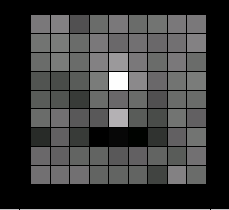
|

|

|
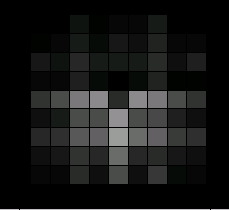
| |

|
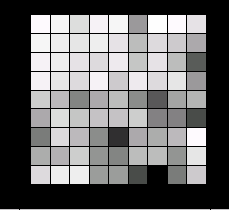
|

|
|
|
| |
6 : Cross Generational Testing on Level 1
Cross Generational Testing | |||||||||
| GHOST | |||||||||
| LEVEL | |||||||||
|
P A C M A N |
|||||||||
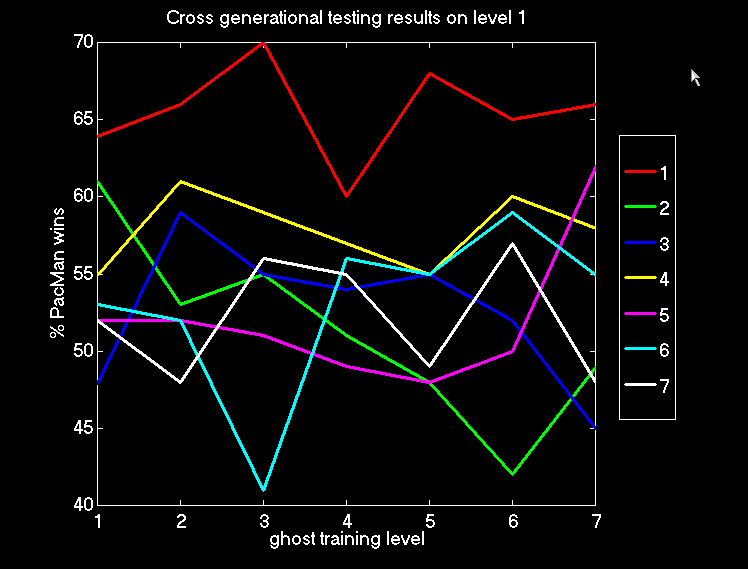
Figure 6.1:
|
6 : Cross Generational Testing on Level 2
| Cross Generational Testing | |||||||||
| GHOST | |||||||||
| LEVEL | |||||||||
|
P A C M A N | |||||||||
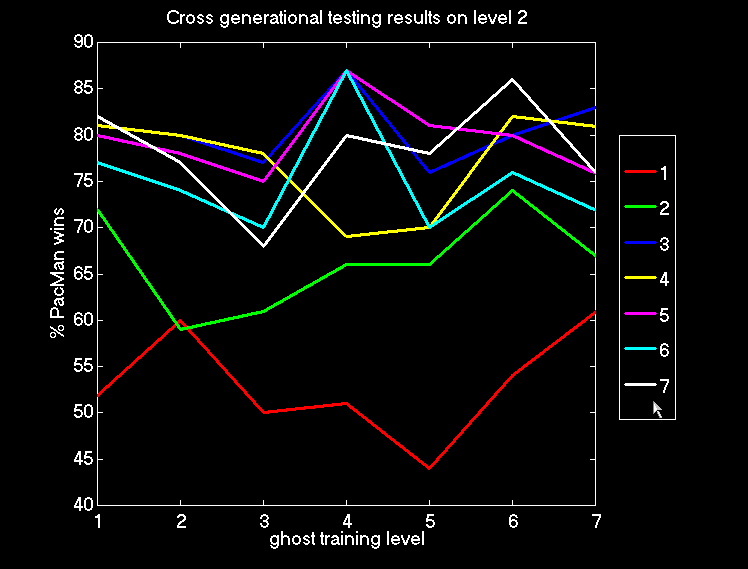
Figure 6.2:
|
6 : Cross Generational Testing on Level 3
| Cross Generational Testing | |||||||||
| GHOST | |||||||||
| LEVEL | |||||||||
|
P A C M A N | |||||||||
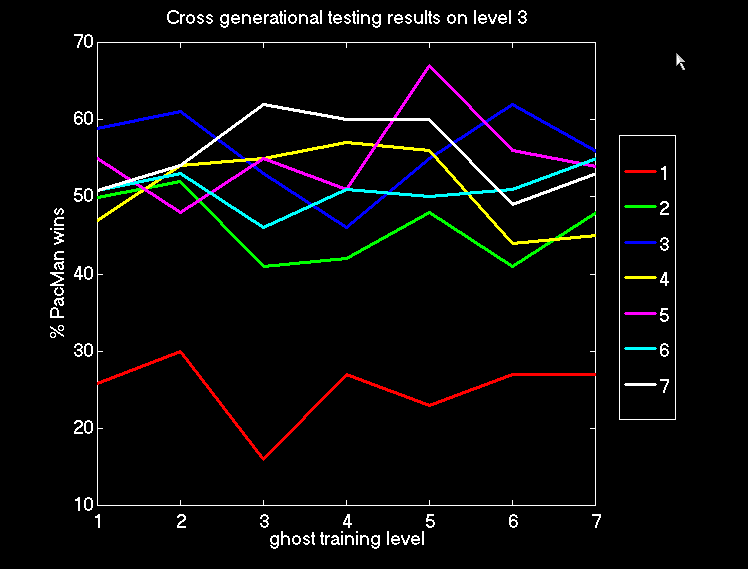
Figure 6.3:
|
A1 : Images " of" " the" Levels

|
Jeremy S. De Bonet jsd@debonet.com |

|
|
|
|